
Her canlı organizmanın kalbinde genomu vardır. Hücre bir bilgisayarsa, genom dizisi yürüttüğü yazılımdır. DNA’yı hücre tarafından işletilen bir yazılım olarak düşünürsek benzer mantıkla nasıl çalıştığını analiz etmek için kendi bilgisayarlarımızı da kullanabiliriz.DNA sadece bilgi deposu değildir,karmaşık şekilde davranabilen fiziksel bir yapıdır.Genomlar binlerce parçadan oluşan inanılmaz kompleks makinelerdir.Günümüzde bazı genlerin nasıl çalıştığını biliyorsakta birçok genin birlikte nasıl çalıştığı anlaşılamamıştır.
-Genetik DNA’yı sadece bilgi olarak görür, bilgideki paternleri arar,genler ve fiziksel görünüş arasındaki bağıntıları araştırır.
-Genomik ise genomu bir makine olarak görür ve parçalarının birlikte nasıl çalıştığını anlamaya çalışır.
Genomik Data Science
Genomik Data Science kısaca veri biliminde bulunan istatistik,makine öğrenmesi gibi metodların genomik problemlere uygulanmasıdır.
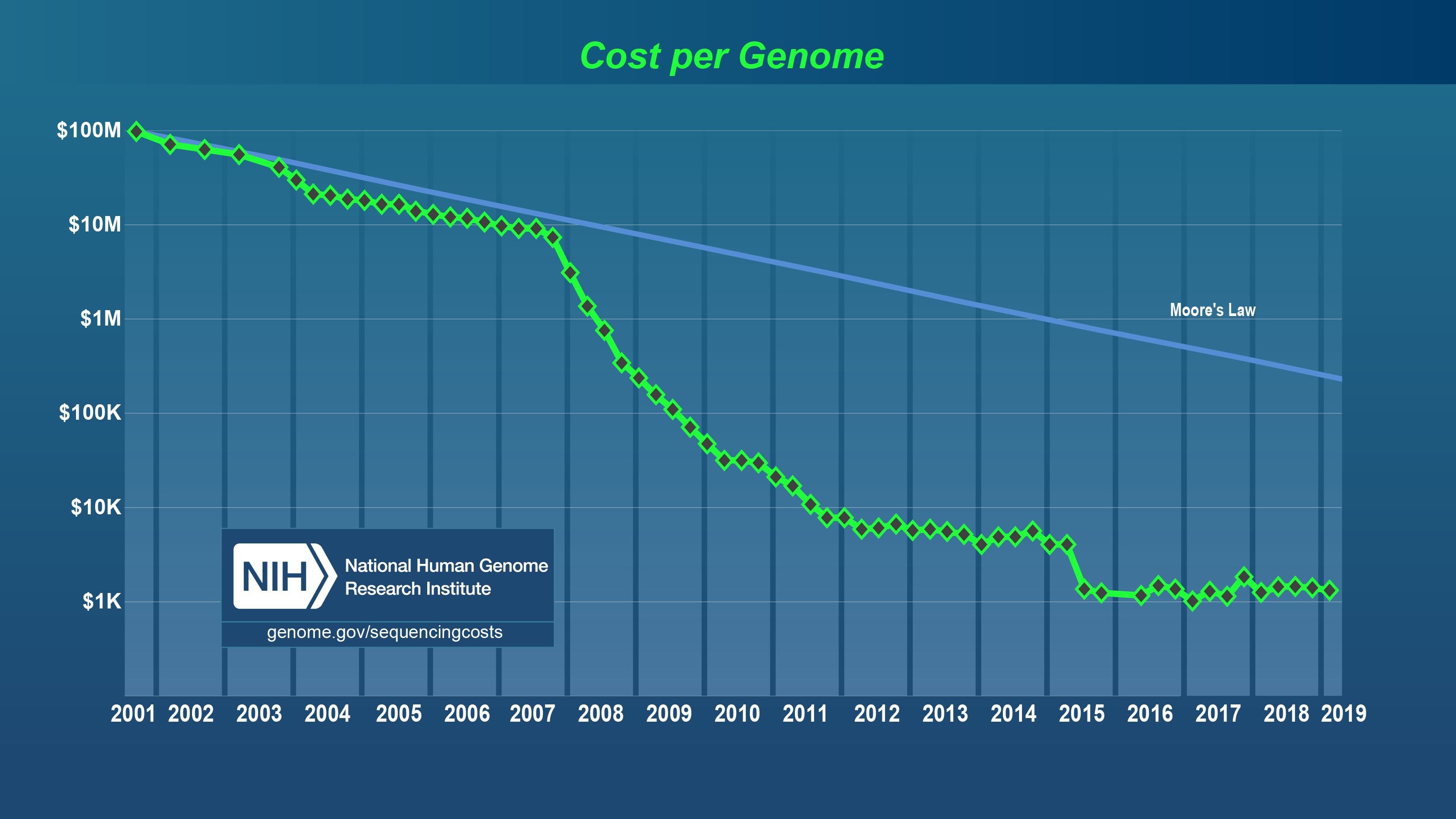
Next generation sequencing sayesinde genomları daha hızlı,ucuz ve başarılı dizileyebilmekteyiz.Örneğin İnsan Genom Projesi 2.7 milyar(geçmişte) dolara gerçekleştirildi günümüzde ise 1000 dolara genomunuzu sekanslayabilirsiniz.Bu nedenle internet üzerinde Petabayt’larca genomik data bulunabilir.
Yaşan bir organizma insanların bu güne kadar ürettiği bütün makinelerden daha karmaşıktır.Bu karmaşıklığı çözmek klasik algoritmaların veya insanın anlama kapasitesinin üzerindedir.Çoğu genetik hastalık ve kanser birden fazla genin etkileşimiyle ortaya çıkmaktadır ve genetik varyasyon bulundurmaktadırlar.
İnanılmaz derecede karmaşıklığa ve veri noktasına sahip datayı analiz etmek için en güçlü silahlardan biri Derin Öğrenmedir,klasik yöntemler genler arasında doğrusal ilişki olduğunu varsayar ki böyle değildir.
Genomik Data Science ile kişiselleştirilmiş ilaç çalışmaları hızlandırılabilir veya canınız sıkıldıysa yere sigara yada sakız atmış insanları tespit etmek için genomlarından yüzlerinin 3 boyutlu versiyonunu oluşturabilirsiniz.
Yaşam ve DNA

Bakteriden balinaya hayat benzer prensiplerle çalışır.Bütün canlılar birbirine yaşam ağacında bağlıdır ve büyük ihtimalle tek bir ortak atadan gelmektedirler.
DNA 4 temel (A,T,G,C) bazın tekrarından oluşan uzun bir polimerdir.Organizmanın nasıl inşa edileceğine dair neredeyse bütün bilgi burada saklanır.
Bu bilginin kendisi ve nasıl işleneceği(epigenetik) zaman içinde değişir,evrimleşir.DNA sonsuza yakın kombinasyonda bilgi taşıyabilir hiç doğmamış insanların veya hiç oluşmamış,hayal gücünüzün sınırlarını zorlayan yeni tür canlıların da kodu burada keşfedilmeyi beklemektedir.
Temel işleyiş
Santral Dogma
DNA yazılımsa proteinler en önemli donanımdır.Proteinler hücre içerisindeki işlerin çoğunu yapan küçük makinelerdir.DNA’daki bilgi ile proteinlere çevirirken mRNA adlı moleküle ihtiyaç duyulur.mRNA ribozom’a gider ve içerdiği bilgiye göre amino asitler birleştirilerek protein sentezlenir.Ribozomlar organik 3 boyutlu yazıcıdırlar.
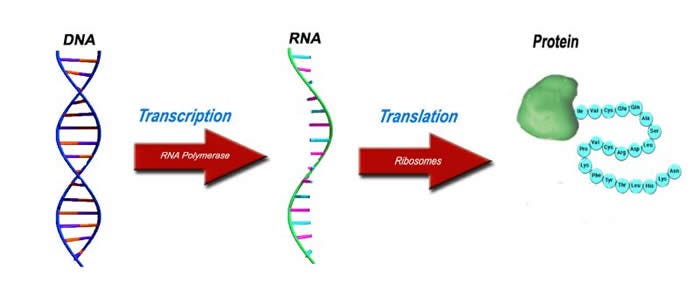
DNA’dan proteine tek yönlü bilgi akışı ve vardır ve basit bir şekilde çalışmaktadır.Bu fikir ne kadar zarif gözüksede günümüzdeki bilgilerimize göre eksik kalmaktadır.
Dogmanın yıkılışı ve karmaşıklık
Şimdi de genomların gerçekten nasıl çalıştığını inceleyelim.
- Ökaryot’ların DNA’sı hücre içine sığabilmesi için histon denen proteinlerin etrafına sarılmıştır, sıkıca paketlenen kısımlar okunamazlar ve metilasyona uğramış kısımların okunması zorlaşır.DNA’nın nezaman açılması gerektiğini düzenleyen mekanizmalar tam anlaşılmamıştır.
- DNA’dan proteine tek yönlü bir bilgi akışı yoktur,proteinler de DNA’ya bağlanarak düzenleyici görev alabilirler.
- mRNA hangi proteinin sentezleneceği bilgisini taşır fakat ne zaman sentezlenmesi gerektiğini bilemez.
- Burada Transkripsiyon faktörler devreye girer,Transkripsiyon faktörler DNA’da özel noktalara bağlanırlar ve yakınında bulunan genlerin ekspresyonunu düzenlerler.
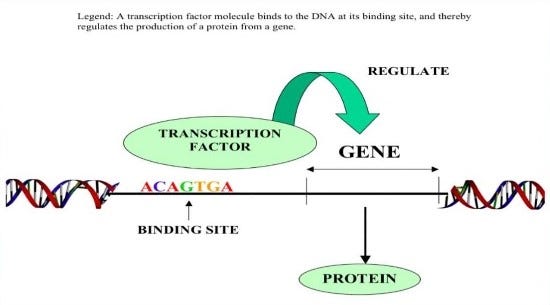
- Aynı genetik bilgiyi taşıyan deri ve sinir hücresi’nin farklı olmalarını gen ekspresyonlarının düzenlenmesine borçludurlar.
Düzenleme görevine miRNA,siRNA,Riboswitch’lerde katılabilir.

NOT : Genom’daki bütün düzenleme mekanizmaları anlaşılmamış olup işleyiş burada anlatılandan daha karışıktır.
Transkripsiyon faktörün(TF) bağlanmasını tahmin etmek
Bir hücrenin çok fazla karışık ve klasik yöntemlerin çalışmasının zor olduğunu gördük.Bu nedenle Derin öğrenme tekniklerini uygulayacağız.Data olarak HepG2 hücre hattını ve JunD TF kullanacağız. HepG2 15 yaşındaki bir Afrikan-Amerikan çocuğun karaciğer dokusundan türetilen ölümsüz hücre hattıdır.

Genomik datanın işlenebilir düzeyde olması için 22. kromozom’u seçiyoruz.Bu Kromozom yaklaşık 50 milyon baz çifti içerir,insanda yaklaşık 3 milyar baz çifti vardır.En büyük kromozom 1. ve en küçüğü ise 22. sırada olandır.
3 milyar baz çiftinden sadece 2 tanesi(özel konumdaki)mutasyona uğrarsa Kistik fibrozis veya çok küçük değişiklikler Hemofili,Renk körlüğü,Kas distrofisi gibi hastalıklara yol açabilir.
Genomik data .FASTA veya .FASTQ formatında saklanmaktadır. Data’nın kitap satırlarına benzer bir görünümü olucaktır.
>chr22
NNNNNNNNNNNNNNNNNNNNNNNNNNN
TCCCAAATTGTGGAAGGAATGTACATTTGAC
Burada DNA’nın tek bir zincirinin içerdiği baz dizimlerini görmekteyiz,DNA’da “N” simgesinin ne işi var diye sorabiliriz, bu kısaca sekanslama işleminde okunan bazın hangisi olduğuna karar verilemediği anlamına gelir.
Sırada genomik bilgiyi kullanabileceğimiz matematiksel formata dönüştürmeliyiz.Gördüğümüz gibi verilerimiz A,T,G,C ve N parçalarından oluşuyor.Bu parçaları One-hot encoding ile ifade edebiliriz örneğin A:[1,0,0,0] veya G:[0,0,1,0] ve N:[0.25,0.25,0.25,0.25] temsil edilebilir.
[[1., 0., 0., 0.],
[1., 0., 0., 0.],
[0., 1., 0., 0.], yeni DNA zincirimiz(tek zincir)
[0., 0., 1., 0.],
[0., 0., 0., 1.]]
Sonrasında zinciri 101’er uzunlukta parçalara bölüyoruz. JunD proteinin nereye bağlanabileceğini bilgisine sahibiz bu nedenle gözetimli öğrenme problemine dönüşüyor.Örneğin parçalara ayırdığımız baz dizilerine JunD bağlanabiliyorsa etiket olarak 1 bağlanamıyorsa 0 olarak ekleyebiliriz.
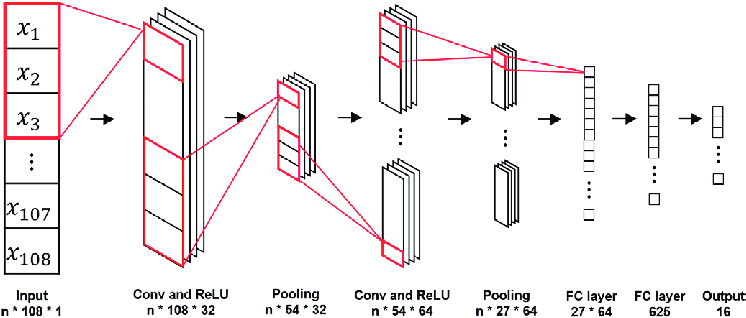
DNA string olduğu için tek boyutludur.Farklı mimariler kullanabiliriz işimize paternleri bulmakta en çok yarayacak mimari ise Evrişimsel sinir ağlarıdır.Genelde görseller (2 boyutlu bilgi) üzerinde kullanılırlar ayrıca,1D CNN’ler ise textleri işlemek için kullanılabilirler.
2D CNN’ler görüntü üzerinden öz nitelik çıkarımı yaparlar,kenarları,köşeleri,renk değişimlerini ve daha karışık paternleri öğrenirler.Benzer şekilde text verisinden de öznitelik çıkarımı yapabilecek filtreler öğrenebiliriz.Modelimiz eğitildikten sonra 101 baz uzunluğundaki DNA parçalarına JunD proteinin hangi olasılıkla bağlanacağını hesaplayabiliriz.
Kromatin erişilebilirliği
JunD proteinin DNA’ya bağlanmasında bir çok faktör vardır: erişilebilirlik,metilasyon,şekil,başka moleküllerin ortamda bulunması.

Kromatin erişilebilirliği: DNA’nın dışarıdan gelen moleküllere ne kadar erişilebilir olduğunu tanımlar.DNA histonlar etrafına sıkıca sarıldığında TF’lere veya başka moleküllere erişilmez olur.Benzer şekilde susturmak istenen genler de paketlenebilir.
Bir bölgenin erişilebilirliği sabit değildir zamanla değişmektedir.Modelimizi eğitirken kromatin erişilebilirliği bilgisini de eklersek daha başarılı tahminlerde bulunabiliriz.
Sonuç olarak: Makine öğrenmesi genomik alanını da geliştirebilir.Büyük genomik veriyi işleyerek kişiselleştirilmiş ilaç ve hastalık tespiti yapılabilir. Ayrıca farklı bir yıkıcı teknoloji olan CRISPR gen düzenleme teknolojisini daha efektif yapmaktadır.
— Kaynaklar —
https://www.oreilly.com/library/view/deep-learning-for/9781492039822/
https://en.wikipedia.org/wiki/Hep_G2
https://en.wikipedia.org/wiki/JunD

Ömer Özgür
DATA SCIENCE-AI TEAM